这两年,AI Agent 无疑是人工智能领域最热门的方向之一。从 OpenAI 推出的 Codex,到 Anthropic 持续升级的 Claude Code,越来越多的 AI 开始具备“自主完成任务”的能力。它们不仅能够理解用户的指令,还可以调用工具、搜索资料、编写代码,甚至直接操作电脑完成复杂工作流程。对于很多用户来说,这也意味着 AI 正在从传统的聊天助手,逐步进化为真正能够帮助人们工作的数字助理。

不过,现阶段大多数先进的 AI Agent 方案都依赖云端服务。无论是 API 调用还是订阅会员,长期使用都会产生不小的成本。尤其是对于需要频繁执行任务、进行网页搜索、资料整理或自动化操作的重度用户来说,Token 消耗和订阅费用往往是一笔不容忽视的开支。

而就在最近,来自法国的 AI 公司 H Company 正式发布了全新的 Holo 3.1 Agent 模型。它最大的亮点在于支持本地部署,并且能够与 OpenClaw 等 Agent 框架进行对接,从而让 AI 获得真正的电脑操作能力。对于拥有 中高端显卡的用户而言,这意味着可以在自己的电脑上搭建一套完全本地化的 AI Agent 系统,无需支付额外订阅费用,也不用担心 Token 限制,实现真正意义上的“无限使用”。
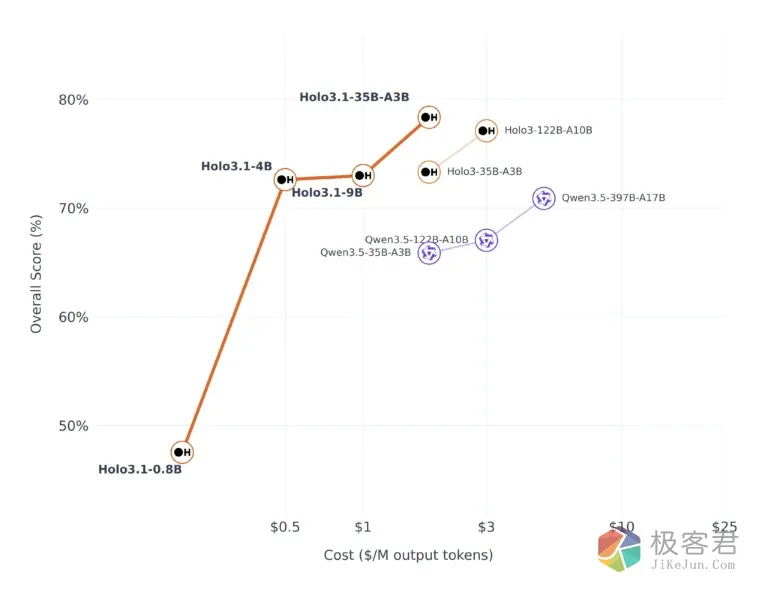
最关键的是 Holo 3.1 作为本地 Agent 专用模型,在各项性能指标都超于了Qwen 3.5 35B A3B模型,在本地部署AI代理绝对是当下的最佳首先开源模型!
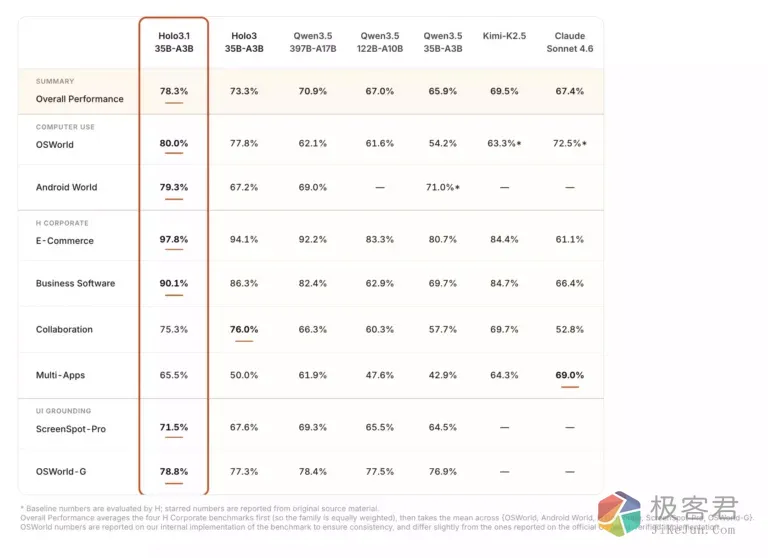
那么 Holo 3.1 的实际效果究竟如何?在接入 OpenClaw 之后,它能否像真人一样打开浏览器、搜索资料、整理信息并完成复杂任务?接下来我们就从部署安装、模型配置以及实际案例测试三个方面,带大家全面体验这款备受关注的本地 Agent 模型。
部署教程
1、安装 Llama.cpp
这次我们同样选择llama.cp来进行部署,因为无论是速度还是性能,llama.cp都优于Ollama 和 LMStudio
| 方案 | 速度 | 易用性 | 适合 |
|---|---|---|---|
| llama.cpp | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 最适合Agent |
| LM Studio | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 日常使用 |
| Ollama | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | API调用 |
| SGLang | ⭐⭐⭐⭐⭐⭐ | ⭐ | 极限性能 |
下载方式:
1、GitHub 下载【点击前往】
2、备用下载 【点击下载】 内含启动脚本
下载后将其进行解压,然后在根目录下创建一个新的文件夹,将其命名为 models,作为接下来存放模型的地方。
2、模型下载
模型该如何选择?根据下方的推荐选择适合自己的对应尺寸的模型即可
| 配置 | 推荐 |
|---|---|
| RTX 4090 24GB | ✅ 35B-A3B Q4_K_M |
| RTX 3090 24GB | ✅ 35B-A3B Q4_K_M |
| RTX 5070Ti 16GB | ✅ 9B |
| RTX 4060Ti 16GB | ✅ 9B |
| Apple Silicon | ✅ 9B GGUF |
模型合集下载:【链接直达】
不同分类尺寸
35B:【点击前往】
9B :【点击前往】
4B :【点击前往】
0.8 :【点击前往】
因为我们使用Llama.cpp来加载本地模型,所有必须选择GGUF格式的模型文件,模型文件含主模型和视觉模型,都需要下载下来
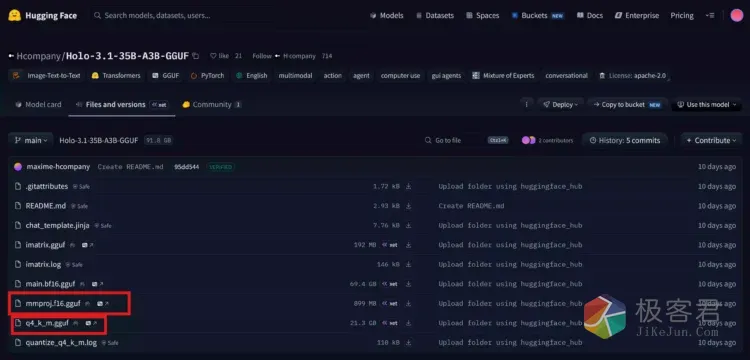
3、启动脚本
将下方的启动脚本另存为一个bat批处理文件,或者【直接下载】脚本文件
@echo off
chcp 65001 >nul
title Holo 3.1 VLM 一键启动器
set LLAMA=llama-server.exe
:MENU
cls
echo ==========================================
echo Holo 3.1 VLM 启动器
echo ==========================================
echo.
echo 1. 8GB显卡推荐(0.8B)
echo 2. 12GB显卡推荐(4B)
echo 3. 16GB显卡推荐(9B)
echo 4. 24GB显卡推荐(35B-A3B)
echo.
echo 5. CPU模式(4B)
echo.
echo 0. 退出
echo.
set /p CHOICE=请选择:
if "%CHOICE%"=="1" goto GPU8
if "%CHOICE%"=="2" goto GPU12
if "%CHOICE%"=="3" goto GPU16
if "%CHOICE%"=="4" goto GPU24
if "%CHOICE%"=="5" goto CPU
if "%CHOICE%"=="0" exit
goto MENU
:: ==========================================
:: RTX 8GB
:: ==========================================
:GPU8
"%LLAMA%" ^
-m models\holo-0.8b.gguf ^
--mmproj models\holo-0.8b-mmproj.gguf ^
-ngl 999 ^
-c 8192 ^
-fa ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--temp 0.2 ^
--top-p 0.9 ^
--host 127.0.0.1 ^
--port 1234
pause
goto MENU
:: ==========================================
:: RTX 12GB
:: ==========================================
:GPU12
"%LLAMA%" ^
-m models\holo-4b.gguf ^
--mmproj models\holo-4b-mmproj.gguf ^
-ngl 999 ^
-c 16384 ^
-fa ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--temp 0.2 ^
--top-p 0.9 ^
--host 127.0.0.1 ^
--port 1234
pause
goto MENU
:: ==========================================
:: RTX 16GB
:: ==========================================
:GPU16
"%LLAMA%" ^
-m models\holo-9b.gguf ^
--mmproj models\holo-9b-mmproj.gguf ^
-ngl 999 ^
-c 24576 ^
-fa ^
--cache-type-k q8_0 ^
--cache-type-v q8_0 ^
--temp 0.2 ^
--top-p 0.9 ^
--host 127.0.0.1 ^
--port 1234
pause
goto MENU
:: ==========================================
:: RTX 24GB
:: ==========================================
:GPU24
"%LLAMA%" ^
-m models\q4_k_m.gguf ^
--mmproj models\mmproj.f16.gguf ^
-ngl 999 ^
-c 65536 ^
--flash-attn on ^
--cache-type-k q8_0 ^
--cache-type-v q8_0 ^
--temp 0.2 ^
--top-p 0.9 ^
--repeat-penalty 1.05 ^
--host 127.0.0.1 ^
--port 1234
pause
goto MENU
:: ==========================================
:: CPU模式
:: ==========================================
:CPU
"%LLAMA%" ^
-m models\holo-4b.gguf ^
--mmproj models\holo-4b-mmproj.gguf ^
-ngl 0 ^
-c 4096 ^
--threads 16 ^
--temp 0.2 ^
--host 127.0.0.1 ^
--port 1234
pause
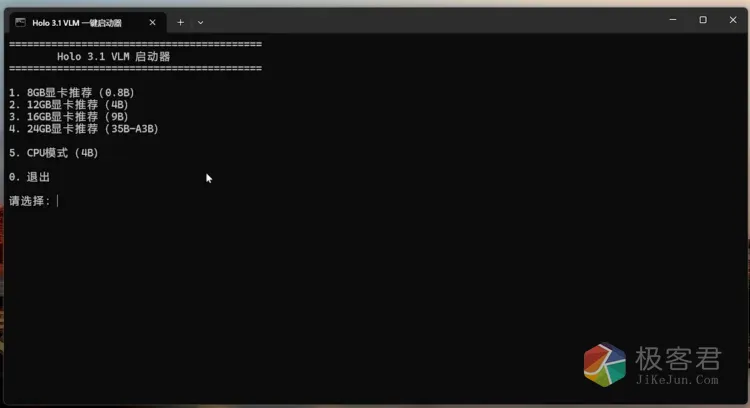
goto MENU注意:脚本的模型文件名称还有路径,你可以自定义修改,相关的启动参数优化已经帮你设置好,当然也可以根据需要进行修改。启动以后会安装Node.js环境等,启动后会看到如下界面,最后选择适合自己的模型大小启动即可
4、安装 Openclaw
当我们部署好本地模型Holo3.1以后,接下来就是将其对接到AI Agent,比如我们可以选择OpenClaw 或者 Hemes 都可以,这次我们先拿小龙虾 OpenClaw 来做测试,只需在电脑上以管理员身份打开 Powershell,然后执行下方的一键安装命令:
Windows
powershell -c "irm https://openclaw.ai/install.ps1 | iex"macOS/Linux
curl -fsSL https://openclaw.ai/install.sh | bash小龙虾的部署过程只需重点注意在模型提供商这里要跟入下截图来进行设置,API Base URL地址填写:http://127.0.0.1:1234/v1
密钥留空不用填写。
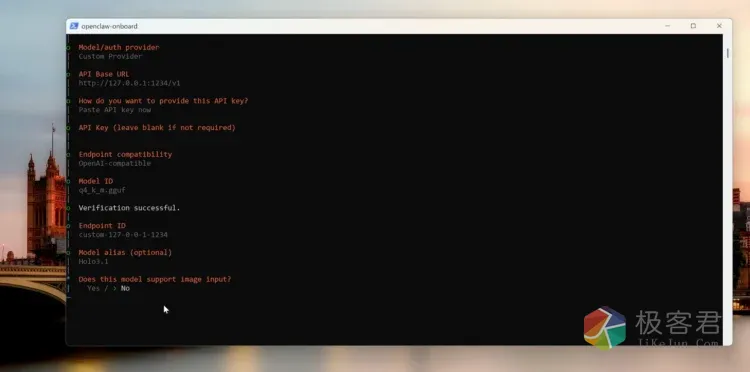
启动模式选择浏览器启动
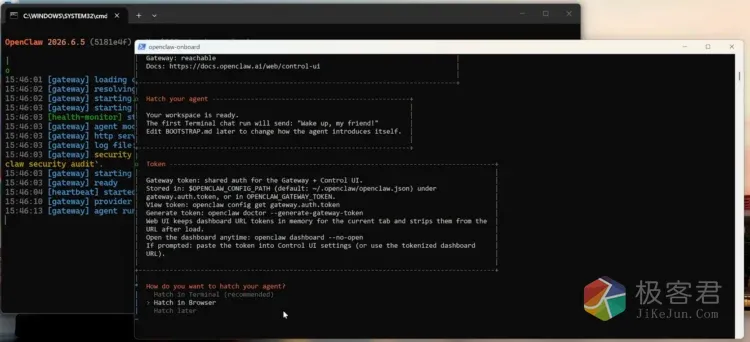
就可以自动进入到OpenClaw的可视化的操作界面,在底部就可以看到正常加载到本地的 Holo3.1 开源模型,Off 意思是自动关闭思考模式,因为作为Agent模型,不需要思考过程,否则启动会非常耗时间。
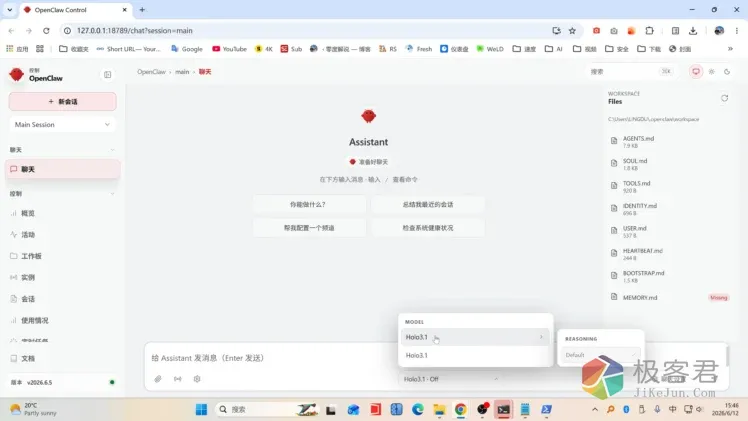
成功启动小龙虾以后,建议安装几个必备的浏览器自动化的 skills
openclaw skills install agent-browser-cli
openclaw skills install use-my-browser安装后再通过命令:openclaw gateway 重启下 OpenClaw 即可!或直接在对话框输入/new 也可以,最后实测,浏览器自动化操作,非常的丝滑流程,最让我意想不到的是,速度确实很快很快!!! 比之前的Qwen 3.5 模型不知快了多少倍,本地模型执行AI Agent 任务,几乎不需要等待的,直接秒执行!
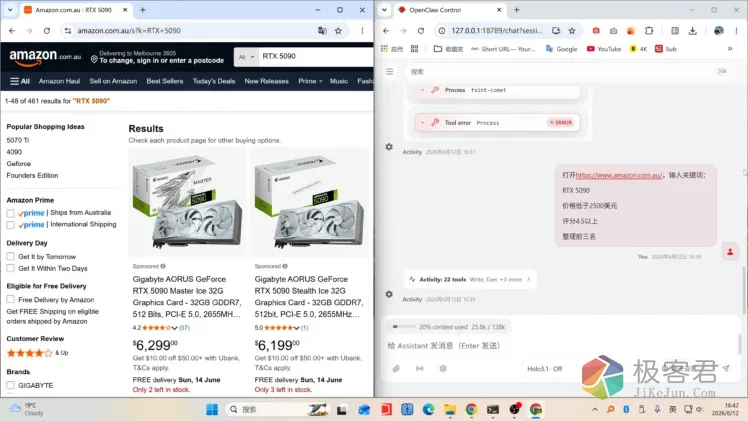
通过开源的Holo3.1模型,你只需一张性能不错的独立显卡,几乎可以代理那些付费的API,如果你的任务不是特别复杂且难度极高的推理。那么这个最新的开源模型就是最佳的本地部署方案!真正完全免费、无需Token、无需绑定任何付费套餐!真正让你实现本地 AI 自由……