在 AI 领域,论文和跑分(Benchmark)有时会骗人,但数百万真人的实测反馈不会。作为全球公认“含金量最高”的 AI 榜单,LMSYS Chatbot Arena 最近更新了 2026 年 1 月的最新排名。
这场没有硝烟的战争中,Google、Anthropic、OpenAI 与新兴的 xAI 正在上演一场精彩的“四国大战”。

一、 诸神之战:Gemini 强势登顶,Claude 紧随其后
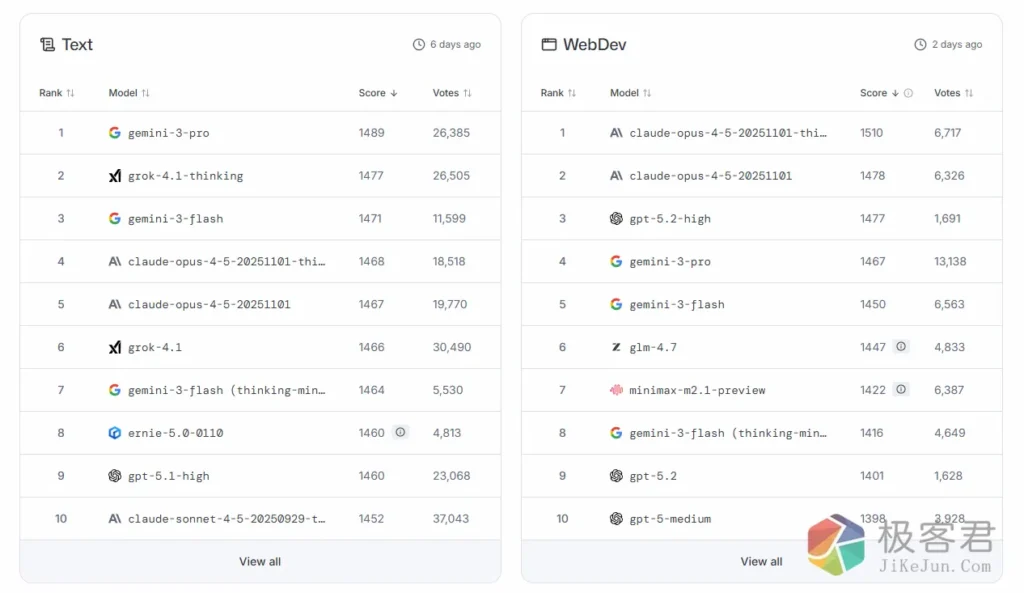
根据最新的 Arena Elo 评分,全球大模型的第一梯队已经发生了微妙的更替:
-
Google Gemini 3 Pro (排名第一,Elo: 1489+) Google 凭借 Gemini 3 Pro 再次证明了其深厚的技术底蕴。该模型不仅在综合对话中表现出色,更在多模态理解(Vision)和超长上下文处理上统治了榜单。无论是创意写作还是复杂逻辑推理,Gemini 3 系列目前是用户公认的“最聪明选择”。
-
Grok-4.1 Thinking (排名第二,Elo: 1477+) 马斯克旗下的 xAI 成为 2026 年最大的黑马。Grok-4.1 特别是其“思维模型(Thinking Mode)”在逻辑链条推理(CoT)上进步神速。它以犀利、不避讳政治敏感话题的风格,在极客群体中获得了极高的投票率。
-
Claude Opus 4.5 (排名第四,Elo: 1468+) Anthropic 的 Claude 4.5 依然是代码和文学创作领域的“心头好”。虽然在绝对总分上略逊于 Google,但它在 Coding(代码竞技场) 子榜单中几乎长期霸榜。用户反馈其回答的“人类感”和“逻辑细腻度”依然是行业天花板。
-
GPT-5.2 (OpenAI,Elo: 1465+) 作为曾经的王者,OpenAI 的 GPT-5.2 表现稳定,但在近期受到激烈的侧翼进攻。它的核心优势在于任务执行的稳定性和庞大的插件生态系统,在日常办公综合体验中仍处于顶尖水平。
二、 细分赛道:各有所长
LMSYS 榜单不仅仅是一个总分排名,它还细分了多个实战赛道,帮助用户根据需求选型:
-
代码之王(Coding Arena): Claude Opus 4.5 与 Gemini 3 Pro 几乎并列第一。如果你是程序员,这两个模型是目前协助编写复杂架构的首选。
-
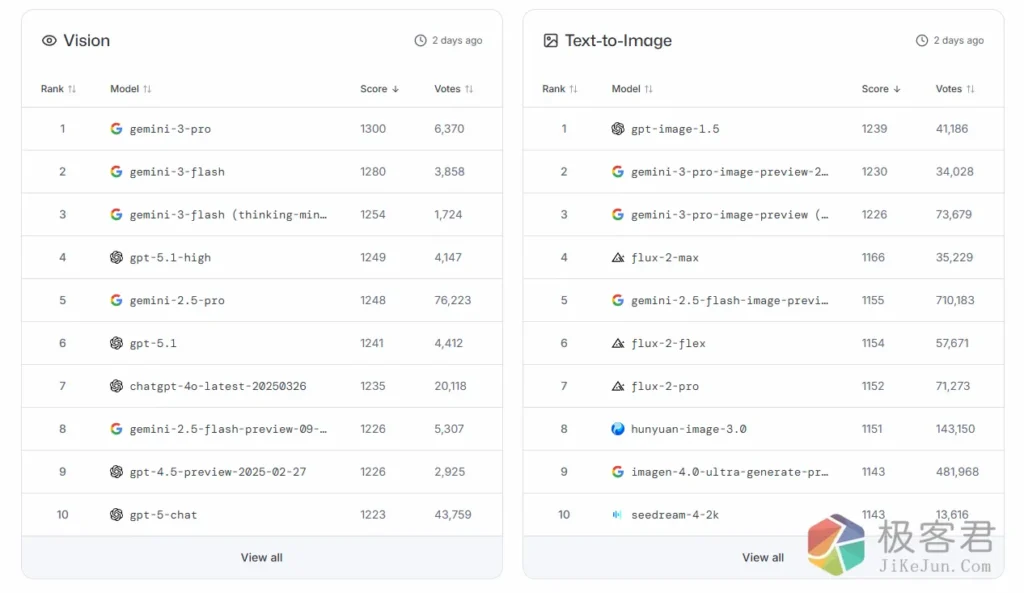
视觉理解(Vision Arena): Gemini 3 Pro 拥有压倒性优势,其对图像细节的捕捉和视频内容的逻辑理解能力,明显领先于竞争对手。
-
国产之光: 值得关注的是,来自中国的 DeepSeek-V3 和 Qwen (通义千问) 展现了极强的韧性。它们在中文推理和数学任务中, Elo 评分已逼近 GPT-5.1,甚至在性价比上远超国外模型。
三、 为什么 LMSYS 榜单最值得参考?
与普通的学术评测不同,LMSYS 采用的是**“盲测对决”**机制:
-
双盲测试: 用户输入一个问题,两个匿名模型同时回答。
-
真人投票: 用户在不知道模型名字的情况下,根据回答质量投票(谁更好、还是打平)。
-
Elo 等级分: 系统根据胜负结果,像计算围棋或足球排名一样动态更新分数。
这种机制彻底杜绝了模型“针对题目刷分”的舞弊可能,真实地反映了模型在真实人类感知中的表现。
四、 给用户的建议
-
如果你追求极致的推理和多模态体验: 请认准 Gemini 3 Pro。
-
如果你是重度开发者或文案写作者: Claude 4.5 会带给你惊喜。
-
如果你希望在社交媒体或个性化搜索中获得更犀利的见解: 试试 Grok-4.1。
-
如果你关注中文逻辑和极致性价比: 关注 DeepSeek 或 Qwen。
结语
AI 的王座从未如此动荡。2026 年的竞技场告诉我们,没有永远的霸主,只有不断的迭代。在这个“模型即基础设施”的时代,LMSYS 排行榜不仅是技术的风向标,更是我们感知 AI 进化最真实的一面窗户。
数据来源说明:本文基于 2026 年 1 月 LMSYS Chatbot Arena (lmarena.ai) 实时榜单数据整理。