你有没有过这样的时刻——对着手机上的语音助手说了半天,心里却犯嘀咕:我这些话,是不是全被传到某个看不见的服务器上了?今天这期,我们干脆把整套实时语音对话 AI 搬回自己电脑里:你说话,它实时听懂、思考、开口回答,全程在本地电脑 上跑完,一个字节都不往外传。

更狠的是——你甚至可以直接拔掉网线,它照样跟你流畅对话。这套方案完全开源、完全免费,用的是 HuggingFace 官方的语音智能体流水线,把语音识别、大模型、语音合成三个开源模型串成一条链路,配上一个会随你声音”呼吸”的可视化界面。整个部署过程我会一步步带你走,Windows 电脑就能搞定,跟着做完,你就拥有了一个真正属于自己、谁也偷听不走的私人语音助手。

第一步:装基础环境
1、 Python 3.10+
推荐使用 Python 3.11 , 安装时务必勾选 “Add Python to PATH”
【点击下载】
2、安装 Git
【点击下载】
3、安装 ffmpeg
PowerShell 里执行下方的命令进行一键安装,装完重开一个 PowerShell 窗口让它生效
winget install Gyan.FFmpeg第二步:装 speech-to-speech
1、先激活环境,power shell 执行下方命令
Set-ExecutionPolicy -Scope CurrentUser RemoteSigned2、执行一键安装命令:
cd C:\
mkdir s2s
cd s2s
python -m venv venv
.\venv\Scripts\Activate.ps1命令行前面出现 (venv) 的绿标意味着成功进入独立的虚拟环境了。
3、安装speech-to-speech 和 Qwen3-TTS 的底层 CUDA 组件
pip install speech-to-speech第三步:准备本地大模型(llama.cpp,解压即用不用编译)
下载最新版llama.cpp
下载两个 zip(按 CUDA 版本,4090 常见 12.4):
- 主程序:llama-b<最新编号>-bin-win-cuda-12.4-x64.zip
- 运行时:cudart-llama-bin-win-cuda-12.4-x64.zip
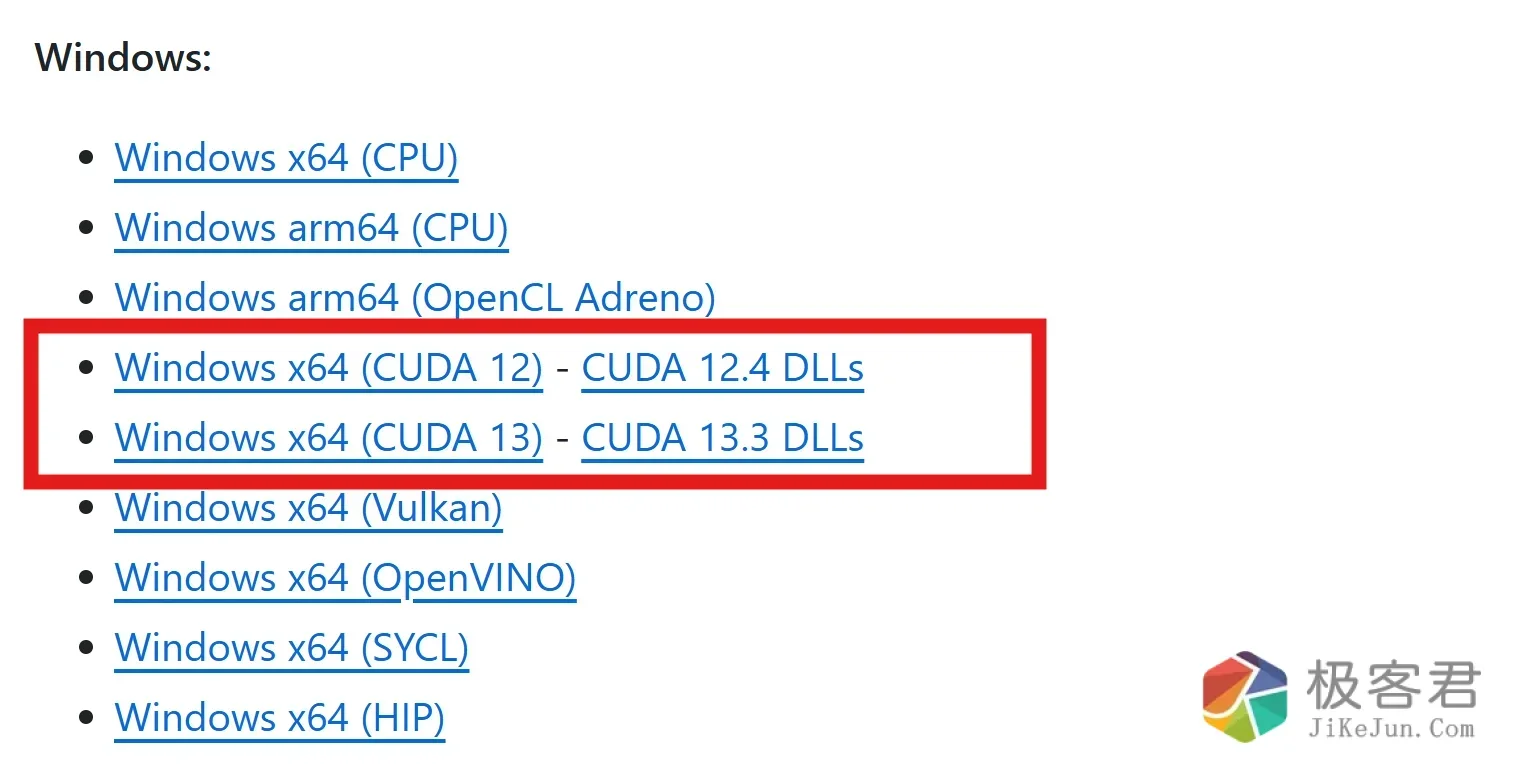
两个都解压到同一个文件夹(比如 D:\llama),合并后里面会有 llama-server.exe 和一堆 .dll。
别下错:13.x 显卡选 cuda-13.3 的两个包;不要下 hip(那是 AMD 的)或 cpu 版。
下载中文模型(在带 (venv) 的窗口里):
python -c "from huggingface_hub import snapshot_download; snapshot_download('unsloth/Qwen3-4B-Instruct-2507-GGUF', allow_patterns='*Q4_K_M.gguf', local_dir=r'D:\llama\models\qwen3-4b')"如果你在安装的过程中出现以下的错误
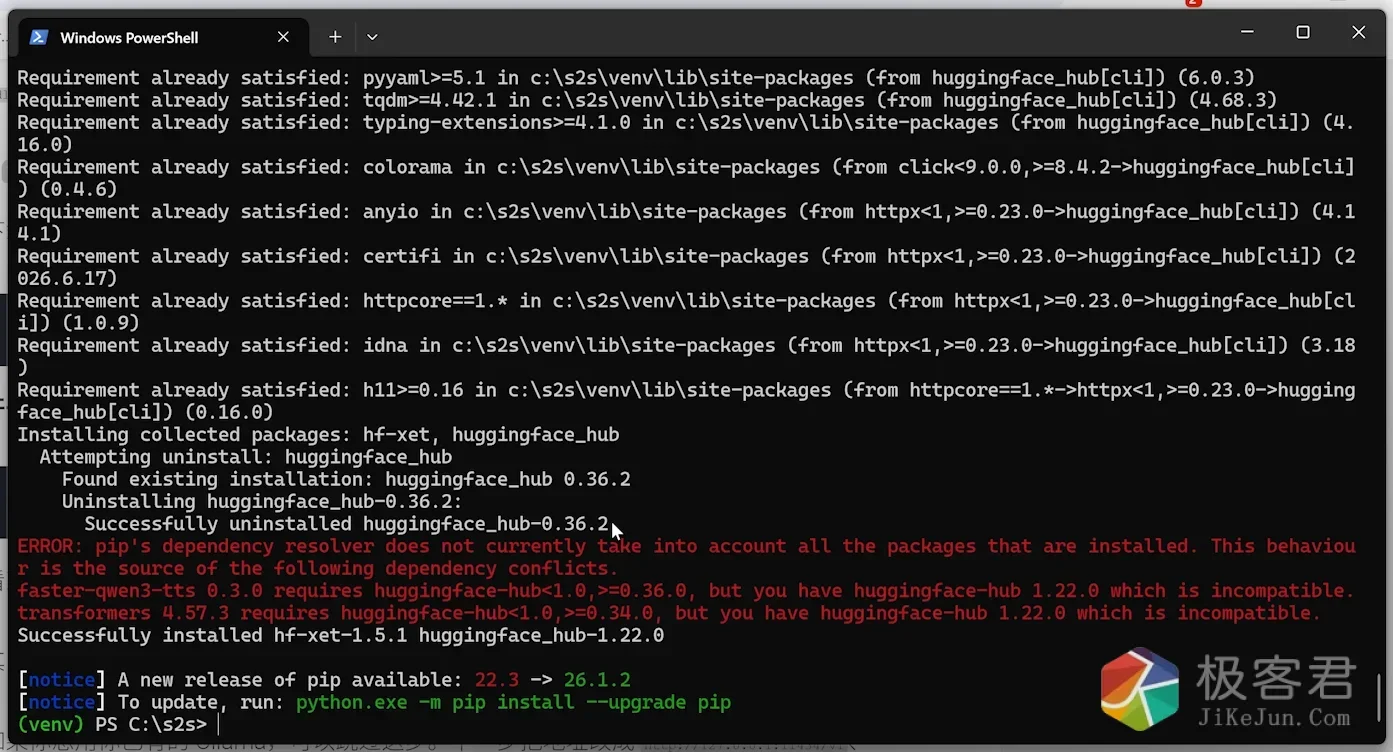
那么主要的原因是”huggingface_hub[cli]” 版本太高了,我们需要将其版本下降下,执行下方的命令即可解决:
pip install "huggingface_hub>=0.36.0,<1.0"
winget install ChrisBagwell.SoX修复或再开一个新 PowerShell 窗口专门跑大模型(全程别关):
cd D:\llama
.\llama-server.exe -m .\models\qwen3-4b\Qwen3-4B-Instruct-2507-Q4_K_M.gguf -c 32768 -fa on --port 8080 -ngl 99看到监听 http://127.0.0.1:8080 就成功了。
其中 -ngl 99 是把所有层放 GPU(4090 显存够),-c 32768 是上下文长度,-fa on 是加速。
如果你想用你已有的 Ollama,可以跳过这步。下一步把地址改成 http://127.0.0.1:11434/v1、模型名改成 qwen3.6:27b (或你自己的本地模型)就行。
第四步:启动语音对话服务
回到第二步那个带 (venv) 的窗口(跑大模型的窗口别动),把下面整段贴进去。注意 PowerShell 换行用的是反引号 `,不是斜杠:
speech-to-speech `
--mode realtime `
--stt whisper `
--stt_model_name openai/whisper-large-v3 `
--language zh `
--llm_backend responses-api `
--model_name "unsloth/Qwen3-4B-Instruct-2507-GGUF" `
--responses_api_base_url "http://127.0.0.1:8080/v1" `
--responses_api_api_key "none" `
--responses_api_stream `
--tts qwen3 `
--qwen3_tts_language zh `
--enable_live_transcription注意:你 venv 里装的 PyTorch 是 CPU 版(不带 CUDA),那么你需要在带 (venv) 的窗口执行(先卸载 CPU 版,再装 CUDA 版):
pip uninstall torch torchaudio -y
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu124几个关键参数的意思:
- –stt whisper + –language zh — 用 Whisper 识别中文,这是普通话对话的核心
- –stt_model_name openai/whisper-large-v3 — 4090 用 large-v3 又准又快;想更快换成 openai/whisper-medium
- –responses_api_base_url — 指向第三步的本地大模型
- –tts qwen3 + –qwen3_tts_language zh — 用 Qwen3-TTS 合成中文语音
- –enable_live_transcription — 开实时字幕(网页上文字逐字出现)
看到 Realtime server listening on ws://localhost:8765/v1/realtime 就说明服务好了。首次启动会下载 Whisper 和 Qwen3-TTS 模型,耐心等。
第五步:打开网页界面(呼吸球)
再开第三个 PowerShell 窗口,进到 voice-chat-client.html 所在目录,起一个本地网页服务:
cd C:\s2s
git clone https://huggingface.co/spaces/smolagents/hf-realtime-voice
cd hf-realtime-voice
pip install -r requirements.txt
uvicorn server:app --port 7860浏览器(用 Chrome 或 Edge)打开:
http://127.0.0.1:7860第一次启动以后,我们需要填写下本地语音地址为:localhost:8765
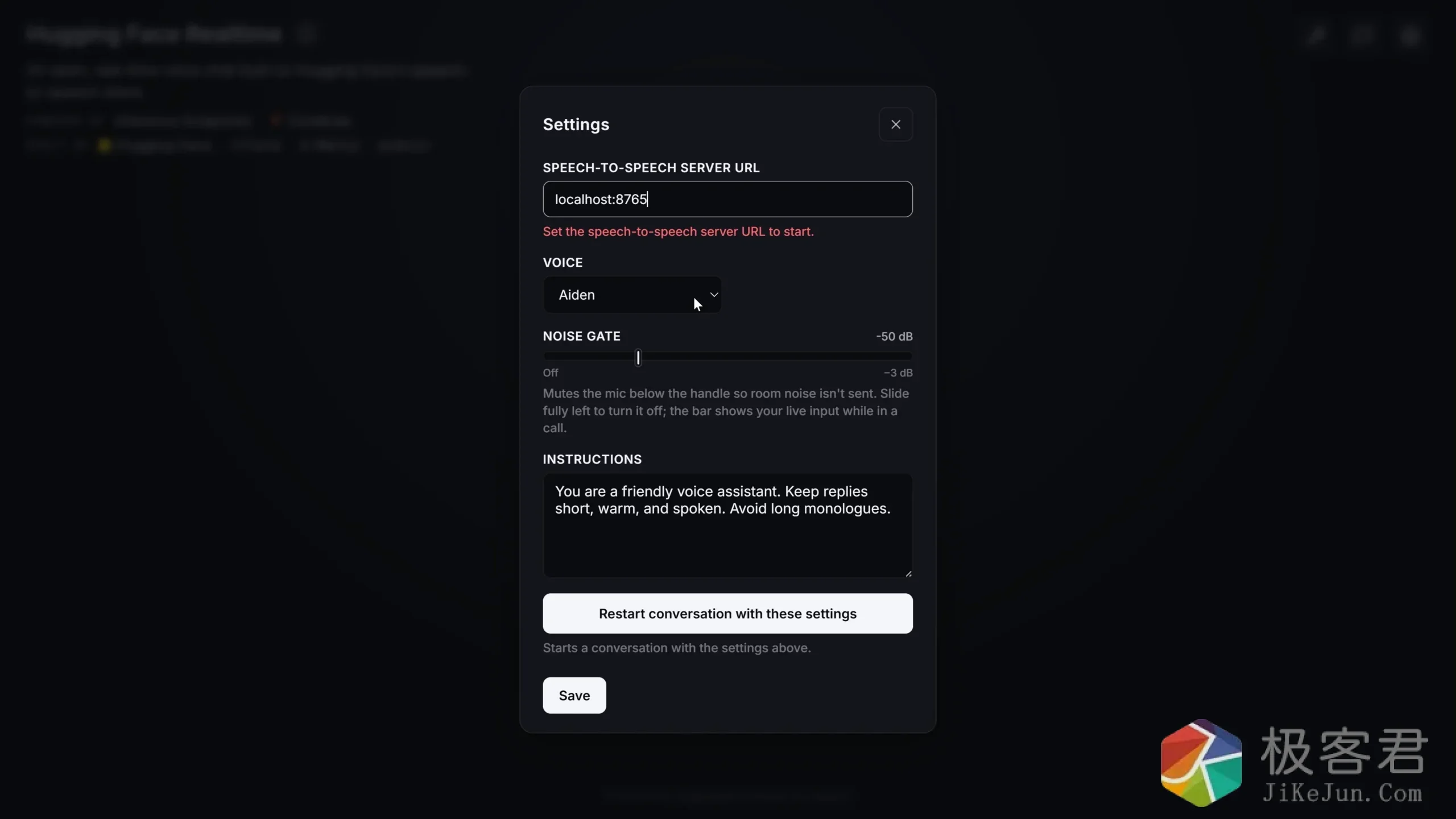
操作: 顶部 WS 地址保持默认 → 点中央的球 → 允许麦克风 → 球变绿色 → 对着麦克风说普通话。
球的颜色会告诉观众现在走到哪一步:绿=就绪、青=在听你说、琥珀=思考中、紫=AI正在回答、红=出错。球会随你和 AI 的音量真实地”呼吸”缩放。

更强模型下载
Qwen3.5 A3B 模型:【点击下载】 或 【更多模型下载】
下载将模型放入D:\llama\models 模型文件夹下,把把启动脚本里的模型文件名称改成你新放入的模型名称即可。
重启电脑后怎么使用?
你可以使用下方这个一键启动脚本来执行,它会自动依次弹出三个服务窗口、等各自加载好、最后打开浏览器。
一键启动脚本【点击下载】
怎么用:
- 把 启动语音对话.bat 下载下来,放一个好找的位置(比如桌面)
- 双击运行
- 它会自动:弹窗口1(大模型)→等20秒→弹窗口2(语音服务)→等30秒→弹窗口3(网页)→等6秒→自动打开浏览器
- 浏览器打开后,进 Settings 填 localhost:8765,点球开始说话
几个要注意的点:
① 那几个”等待秒数”可能要微调。 脚本里给大模型留了20秒、语音服务留了30秒。如果你机器加载慢,可能网页窗口起来了、语音服务还没好,导致第一次点球连不上——这时等语音服务窗口出现 running on http://0.0.0.0:8765 之后,刷新一下浏览器再点球就行。如果你发现每次都要等更久,告诉我,我把秒数调大。
② 三个服务窗口别关。 脚本主窗口(黑色那个提示信息的)可以关,但弹出的三个 cmd 窗口要留着,它们就是在跑服务。关掉哪个哪个服务就停了。
③ 第一次双击如果 Windows 拦截。 可能弹”Windows 已保护你的电脑”,点”更多信息”→”仍要运行”即可(因为是本地脚本、没有数字签名,属正常)。
④ 想改中文提示词。 网页 Settings 里的 Instructions(中文提示词)浏览器会自己记住,脚本不管这个,填一次以后就在。
先双击试一次,看三个窗口能不能都正常起来、浏览器能不能自动打开。如果哪个窗口报错、或者点球连不上,把情况告诉我,我帮你调脚本的等待时间或路径。
Linux方案:
WSL2(原生装不上时用这个)
WSL2 是 Windows 自带的 Linux 子系统,4090 能直通,Linux 依赖装起来最顺,对观众来说仍然是”在 Windows 电脑上”。
装 WSL2(管理员 PowerShell):
wsl --install -d Ubuntu重启后设个用户名密码,开始菜单搜 “Ubuntu” 进 Linux 终端。在里面跑 nvidia-smi 能看到 驱动版本号 就说明 GPU 直通成功了。
在 Ubuntu 里装(跟 Linux 一样):
sudo apt update && sudo apt install -y python3-venv ffmpeg
python3 -m venv ~/s2s && source ~/s2s/bin/activate
pip install "qwentts-cpp-python==0.3.0+cu124" -f https://huggingface.co/datasets/andito/qwentts-cpp-python-wheels/tree/main/whl/cu124
pip install speech-to-speech
pip install "llama-cpp-python[server]"启动命令和正文第三、四步一样,只是换行符改回 Linux 的斜杠 \、路径用 Linux 风格。网页部分照旧——WSL 里跑 python3 -m http.server 9000,Windows 上的 Chrome 直接访问 http://127.0.0.1:9000/voice-chat-client.html(WSL2 会自动把端口转发到 Windows)。