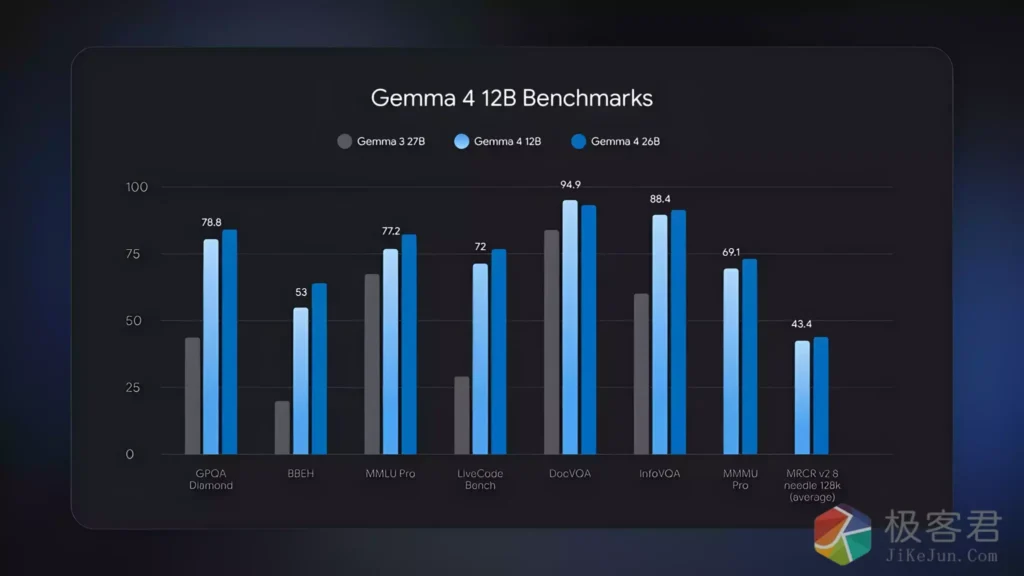
Google 最近正式发布了 Gemma 4 12B,这是 Gemma 系列最新的开放权重模型之一。相比上一代产品,Gemma 4 不仅拥有更强的推理能力,还加入了多模态支持,可以处理文本、图片甚至音频内容。

对于喜欢本地部署 AI 的用户来说,Gemma 4 12B 最大的吸引力在于:
- 仅 120 亿参数
- 支持消费级显卡运行
- 支持多模态输入
- 支持超长上下文
- 可通过 llama.cpp 本地部署
那么它的实际表现如何?本文将介绍本地部署方案以及 5 项完整测试方法。
Gemma 4 12B 有哪些亮点?
Gemma 4 12B 是 Google DeepMind 推出的开放权重模型。
主要升级包括:
1. 多模态支持
Gemma 4 不仅支持文本输入,还支持:
- 图片理解
- 音频理解
- 多模态推理
例如:
- 分析截图
- 理解照片内容
- 总结音频内容
- 视频语音理解
2. 超长上下文
Gemma 4 官方支持最高:
256K Context
这意味着:
- 超长 PDF
- 整本电子书
- 大型代码项目
都可以一次性进行分析。
3. 本地运行门槛较低
即使是 RTX 3060 12GB 这样的主流显卡,也能运行 Gemma 4 12B 的量化版本。
推荐配置:
| 显存 | 推荐模型 |
|---|---|
| 8GB | IQ2_XS |
| 12GB | Q4_K_M |
| 16GB | Q6_K |
| 24GB | Q8_0 |
对于 RTX 4090 用户来说,Q8_0 基本已经接近 BF16 原版效果。
部署步骤:
1、下载 gemma-4 12B 开源模型
【点击前往】
进入以后不仅要下载主模型,还需要下载对应的视觉模型
当然如果你的显存比较小,想在4G、6G显存上跑这个开源模型,那么可以下载更小更细分的量化模型,你可以去下载由 Unsloth 提供的更多的量化模型
量化模型下载:【点击获取】
2、安装最新版 llama.cpp
部署本地开源模型,推荐使用完全开源的llama.cpp,无论是推理速度、兼容性、还是可玩性,都可以实现高度自定义,尤其当然你需要同时使用视觉模型,Agent 代理,对接Hermes、OpenClaw 小龙虾等,它都是非常可靠且稳定的选择!
【点击前往】
下载解压后,在根目录下创建models文件,然后将之前下载的模型全部放入进去,包含主模型和视觉模型
3、创建启动脚本
新建一个文本文档,将下方的启动脚本贴入进去,然后另存为启动.bat 批处理脚本即可,保存的格式需要 UTF-8 ,脚本里的模型文件你可以自己修改自定义,但是对应的模型都必须放在models文件下。
启动脚本获取:【点击下载】
或通过下方的代码手动创建
@echo off
chcp 65001 >nul
title Gemma 4 启动器
:menu
cls
echo.
echo ==========================================
echo Gemma 4 智能启动菜单
echo ==========================================
echo.
echo 【纯文本模式】
echo.
echo 1. 6GB显存 (Gemma 4 4B Q4)
echo 2. 8GB显存 (Gemma 4 12B IQ2)
echo 3. 12GB显存 (Gemma 4 12B Q4)
echo 4. 16GB显存 (Gemma 4 12B Q6)
echo 5. 24GB显存 (Gemma 4 12B Q8)
echo.
echo 【图片理解模式】
echo.
echo 6. 12GB显存 + 图片理解
echo 7. 16GB显存 + 图片理解
echo 8. 24GB显存 + 图片理解
echo.
echo 【极限模式】
echo.
echo 9. BF16视觉模式 (4090/5090推荐)
echo.
echo 0. 退出
echo.
set /p choice=请选择模式:
if "%choice%"=="1" goto VRAM6
if "%choice%"=="2" goto VRAM8
if "%choice%"=="3" goto VRAM12
if "%choice%"=="4" goto VRAM16
if "%choice%"=="5" goto VRAM24
if "%choice%"=="6" goto MM12
if "%choice%"=="7" goto MM16
if "%choice%"=="8" goto MM24
if "%choice%"=="9" goto BF16
if "%choice%"=="0" exit
goto menu
:VRAM6
cls
echo 启动 Gemma 4 4B Q4...
llama-server ^
-m models\gemma-4-4B-it-Q4_K_M.gguf ^
-ngl 999 ^
-c 8192 ^
--host 127.0.0.1
goto end
:VRAM8
cls
echo 启动 Gemma 4 12B IQ2...
llama-server ^
-m models\gemma-4-12B-it-IQ2_XS.gguf ^
-ngl 999 ^
-c 8192 ^
--host 127.0.0.1
goto end
:VRAM12
cls
echo 启动 Gemma 4 12B Q4...
llama-server ^
-m models\gemma-4-12B-it-Q8_0.gguf ^
-ngl 999 ^
-c 186753 ^
--host 127.0.0.1
goto end
:VRAM16
cls
echo 启动 Gemma 4 12B Q6...
llama-server ^
-m models\gemma-4-12B-it-Q6_K.gguf ^
-ngl 999 ^
-c 32768 ^
--host 127.0.0.1
goto end
:VRAM24
cls
echo 启动 Gemma 4 12B Q8...
llama-server ^
-m models\gemma-4-12B-it-Q8_0.gguf ^
-ngl 999 ^
-c 186753 ^
--host 127.0.0.1
goto end
:MM12
cls
echo 启动 Gemma 4 12B Q4 多模态...
llama-server ^
-m models\gemma-4-12B-it-Q8_0.gguf ^
--mmproj models\mmproj-gemma-4-12B-it-Q8_0.gguf ^
-ngl 999 ^
-c 186753 ^
--host 127.0.0.1
goto end
:MM16
cls
echo 启动 Gemma 4 12B Q6 多模态...
llama-server ^
-m models\gemma-4-12B-it-Q6_K.gguf ^
--mmproj models\mmproj-F16.gguf ^
-ngl 999 ^
-c 32768 ^
--host 127.0.0.1
goto end
:MM24
cls
echo 启动 Gemma 4 12B Q8 多模态...
llama-server ^
-m models\gemma-4-12B-it-Q8_0.gguf ^
--mmproj models\mmproj-gemma-4-12B-it-Q8_0.gguf ^
-ngl 999 ^
-c 186753 ^
--host 127.0.0.1
goto end
:BF16
cls
echo 启动 Gemma 4 BF16 视觉模式...
llama-server ^
-m models\gemma-4-12B-it-BF16.gguf ^
--mmproj models\mmproj-gemma-4-12B-it-bf16.gguf ^
-ngl 999 ^
-c 186753 ^
--host 127.0.0.1
goto end
:end
echo.
echo ==========================================
echo 服务启动完成
echo.
echo 浏览器打开:
echo http://127.0.0.1:8080
echo ==========================================
echo.
pause启动脚本后即可看到下方的选项,最后根据自己的需要启动对应的模型

llama.cpp 部署 Gemma 4 12B
如果使用 GGUF 版本部署,需要下载:
主模型:
- gemma-4-12B-it-Q4_K_M.gguf
- gemma-4-12B-it-Q6_K.gguf
- gemma-4-12B-it-Q8_0.gguf
如果需要图片理解功能,还需要下载:
- mmproj-gemma-4-12B-it-Q8_0.gguf
Gemma 4 12B 最大的价值并不是参数数量,而是在模型体积与能力之间取得了不错的平衡。
它同时具备:
- 文本推理
- 编程能力
- 图片理解
- 音频理解
- 超长上下文
对于拥有 RTX 3060、4060Ti、4070、4090 等显卡的用户来说,Gemma 4 12B 都是一个非常值得体验的本地 AI 模型。
如果你正在寻找一个能够兼顾性能、显存占用和多模态能力的开放模型,那么 Gemma 4 12B 值得加入你的测试清单。