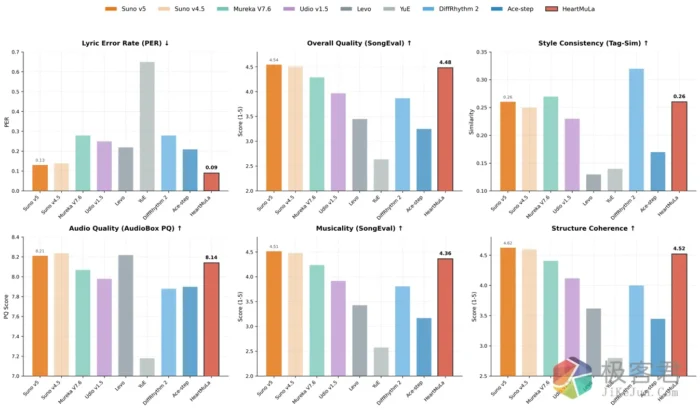


2026年1月20日,智谱AI正式发布并开源了其最新一代轻量化旗舰模型 GLM-4.7-Flash。
作为GLM-4系列的最新迭代成员,这款模型不仅在性能上实现了跨代级的跃迁,更通过“开源+免费API调用”的双重组合拳,彻底引爆了开发者社区。以下是关于 GLM-4.7-Flash 的深度解读。
核心亮点:30B 参数下的“混合思考”利器
GLM-4.7-Flash 采用了创新的 MoE(混合专家)架构,总参数量为 30B,但在实际任务处理中,激活参数量仅为 3B。这种设计在维持极高性能的同时,极大地降低了推理成本和响应延迟。
1. 独创的“交替思考”机制(Interleaved Thinking)
与传统模型“思考完再回答”不同,GLM-4.7-Flash 具备在复杂任务中实时调整逻辑的能力。
-
分步动作: 在 Agent 自动化工作流中,它能根据每一步的反馈(如终端输出或工具调用结果)即时修正接下来的策略。
-
上下文思维保持: 在长对话(如复杂 Debug)中,它能记住多轮之前的架构决策逻辑,避免“前言不搭后语”。
2. 开发者最爱的“代码推土机”
智谱对该模型进行了深度的代码垂直领域优化:
-
前端审美优化(Vibe Coding): 它不再只是生成“能运行但丑陋”的代码,而是更倾向于使用现代设计模式、合理的配色和间距。
-
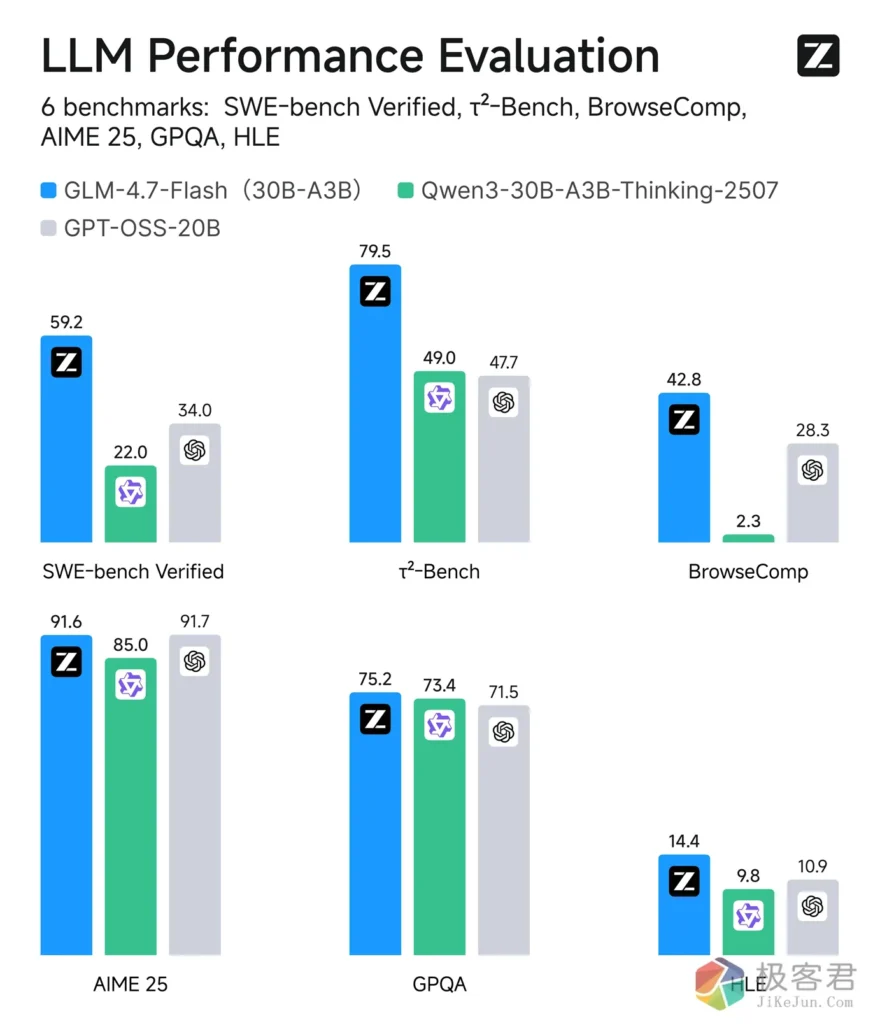
SOTA 级表现: 在 30B 级别的同规格模型测试中,其代码生成和逻辑推理能力超越了阿里 Qwen 和 OpenAI 的同类轻量化模型。
战略级调整:全面替代 GLM-4.5-Flash
随着新模型的发布,智谱在开放平台 BigModel.cn 上同步更新了服务策略:
-
即刻免费: GLM-4.7-Flash 即日起上线,所有用户均可免费调用 API。
-
平滑过渡: 现有的 GLM-4.5-Flash 将于 2026年1月30日下线。届时,所有指向 4.5 版本的 API 请求将自动路由至性能更强的 4.7 版本,开发者无需手动更改业务逻辑。
为什么说它是“本地部署”的理想选择?
由于 GLM-4.7-Flash 已经正式开源,并获得了 vLLM 和 SGLang 等主流推理框架的原生支持,它正迅速成为私有云和本地 AI 助手的首选:
-
低显存占用: 得益于 3B 的激活参数,主流消费级显卡即可流畅运行。
-
128K 上下文: 即使是轻量化版本,依然支持长达 12.8 万 token 的处理能力。
结语:国产大模型进入“普惠”时代
从 GLM-4 到 GLM-4.7,智谱 AI 展现了惊人的迭代速度。而将如此高性能的 30B MoE 模型直接开源并免费开放 API,无疑降低了 AI 应用的创新门槛。对于广大开发者而言,这不仅是一个性能更强的工具,更是一个低成本实现复杂 Agent 的绝佳机会。